
In this article, let’s step back from coding a little bit. We are going to discuss how C++ was born and how it’s been evolving ever since. We’ll only have a brief overview of what happened in the last 40 years, then we will focus on how the C++ programming language is evolving, and where the decisions are taken.
Non-standard C++
The language started out as an extension of the C programming language which itself was an improved version of B. In 1979, the Danish computer scientist, Bjarne Stroustrup started to work on an extension that was called “C with classes”.
Yet, we cannot tell that C++, or at the moment “C with classes” is simply based on C. While Stroustrup was working on his PhD thesis, among other languages he learnt Simula. Simula is considered the first object-oriented programming language. One could create classes and organize them into hierarchical models.
Bjarne loved its expressiveness.
If you think about the history of innovation, great things are rarely born out of the blue. Great things are born when ideas have sex with each other. Stroustrup wanted to combine the humanly understandable relationships introduced by Simula with the sheer power of a low-level language, such as C. That’s how the idea of “C with classes” was born.
It was delivered as a preprocessor of the C compiler, called Cpre. It already included classes and inheritance, public and private access levels, friends, constructors and destructors, assignment operator overloading, inlining and default arguments.
In 1982, Stroustrup started to develop a new language based on his “C with classes” which he named C++, referring to the increment operator (++) in C. Additional new features were added such as virtual functions, function and operator overloading, references, consts, the dreaded new and delete keywords for memory allocations, etc.
It was not a preprocessor for the C compiler anymore, but the features were implemented as part of a standalone compiler called Cfront.
Bjarne Stroustrup continued to work on the language and 7 months after I was born, in 1985 he released the first edition of his book called The C++ Programming Language. At that point, C++ was not a standardized language. This book was the de-facto reference to the language.
A new version, C++ 2.0 came out 4 years later in 1989. in the same year when the Iron Curtain fell. Yes, C++ is that old.
The language was finally standardized
Sixteen years after the initial release and nine years after the second version, in 1998, the language was finally standardized based on C++ 2.0 and it was released as C++98. Five years later C++03 was released, but it was mostly about bug fixes.
C++ was evolving really slowly. No new version was released for 8 years, until 2011.
Let’s stop for a second.
What does it even mean to standardize a language? And how is C++ different from Java or Python in that sense?
The International Standardization Organization (ISO) has a subcommittee responsible for “Programming languages, their environments and system software interfaces”, it’s the ISO/IEC JTC 1/SC 22 subcommittee. This committee has several different workgroups, WG21 is the one responsible for standardizing C++.
On the internet language, people working on the C++ standardization usually refer to it simply as WG21.
In contrast, Java is owned by the tech giant Oracle. Therefore Java is not standardized. One can consider Oracle’s official implementation as the standard, but it doesn’t correspond to any formal standardization.
Python is managed by the Python Software Foundation. Its mission is “to promote, protect, and advance the Python programming language, and to support and facilitate the growth of a diverse and international community of Python programmers”.
The benefits of standardizing a language are
- you know the language won’t randomly change
- if you want to write your own compiler/interpreter for the language, you have a very clear document defining how a language should behave in almost all circumstances.
Standards - just like legal texts - are difficult to read and are lengthy in order to cover all the details. But does the C++ standard define exactly how the language should behave in all the circumstances?
Actually, it doesn’t. About 2000 pages are not enough for that! While reading the standard, we will encounter 3 different categories where we won’t know how our software would behave.
- Unspecified behaviour
- Implementation-defined behaviour
- Undefined behaviour
Unspecified behaviour leaves to the compiler implementers to define the behaviour without the obligation of documenting it. E.g. the outcome of comparing the addresses of local variables is unspecified behaviour.
Implementation-defined behaviour is very similar to unspecified, but in this case, the implementers must document their decision. Think about the number of bits in a byte or default integer types, those are implementation-defined.
Undefined behaviour is the worst. It means that rules are broken, and the compiler is entitled to do anything without guaranteeing us anything. If we are lucky our code would crash, but maybe it will produce logically non-sense, even non-deterministic results. For example, accessing uninitialized variables is undefined behaviour.
How does the committee work?
It would be too simple for us to stop at the level of WG21.
Let’s jump into the details.
The WG21 is organized into a pipeline of three stages.
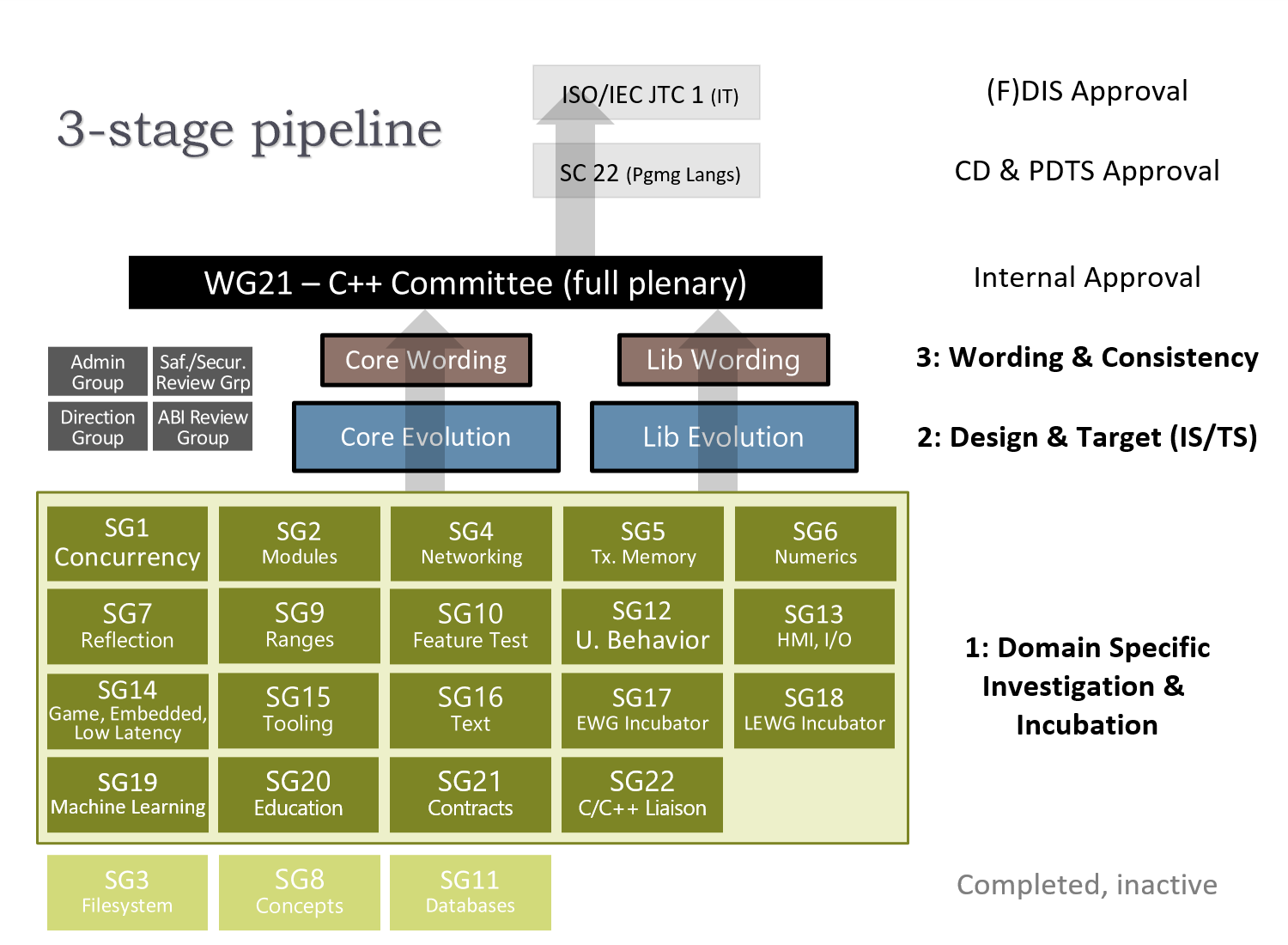
In the first stage, you find study groups (SG). Since the beginning of the C++ standardization, there have been 24 study groups and 19 are still active. These groups are working on proposals for their own areas of expertise. For example, SG9 is responsible for ranges evolution, SG7 for reflection and SG1 for concurrency.
Once a study group considers a proposal ready for the next stage, the proposal goes to one of the two groups of stage 2:
- Core Language Evolution (EWG)
- Library Evolution (LEWG)
Once the proposal is approved at stage 2, it advances to stage 3 where the Core Language Wording Group (CWG) or the Library Wording Group (LWG) makes sure that the new changes will be consistently and properly worded.
Once a proposal went through all these stages, it can be accepted or actually declined by the full plenary C++ Committee, by WG21. A recent such proposal is P0847R7, which is going to be part of C++23 and it’s usually just referred to as deducing this. With this new language feature, we get “a way to tell from within a member function whether the expression it’s invoked on is an lvalue or an rvalue; whether it is const or volatile; and the expression’s type”. If you are interested in further details, follow this link.
A proposal might be sent back to previous stages several times or can be rejected completely. For example, P2012R0 is having a hard time. Their authors want to address a long-known and quite serious issue with range-based for loops (check the details here) and while they had quite some support, in the end, the EWG rejected it still hoping for a future “perfect” solution…
But who can vote and who can work on these standards and proposals?
Let’s answer the easier question. Anyone who is willing to work on the evolution of C++ is welcome to do so. Anyone can write, submit and present a proposal.
At the same time, not everyone who goes to a meeting can actually vote. The committee is built up by the national bodies. In other words, each country’s own standardization organization delegates some people to the international group. At the international meetings, each country has one vote to determine the ISO decision.
For example, my employer, Amadeus is part of the French national body through AFNOR, the French standardization organization. We have a representative at the meetings of the AFNOR, but Amadeus doesn’t have its own delegate at the ISO meetings. The members of the French national body, including Amadeus, choose who can vote at the international meeting representing the French opinion.
It’s worth emphasizing the fact that while voting is possible only for the national bodies, anyone can participate at the meetings. They are open and everyone can go and discuss/defend their proposals. Most of the important work is done through these open discussions. The meetings used to be face-to-face full weeks sessions, but with the COVID they became virtual. You can find more information about the meetings and participation here.
Standards are released on a schedule
Since the release of C++11, the committee is dedicated to following a predictable train-like model. The analogy is - luckily - not about SAFe. It refers to the timetable of trains. Every three years there is a new version to be released. It does not matter how much a fix or a new feature is expected. If it’s not ready when the next train departs, the feature will not be on that train. The train doesn’t wait. The feature missing its train will wait for the next one. It’ll come in 3 years. The original idea was to have every second version packed with new features and the others to include mostly minor additions and bug fixes. The reality hasn’t met this expectation yet as after C+11 the next “major” release was C++20. It’s still to see if C++26 can be a major release. Nevertheless, the train-like model is respected, we have a new release every 3 years. C++11, C++14, C++17, C++20…
Setting a predictable schedule of release dates into stone is useful to avoid special treatment for certain features that are either highly waited for or that are supported by people with bigger authority over the committee.
Besides, the schedule also ensures a high level of predictability of the language evolution. While nobody can know what exactly will be included in the next release, we pretty much know when it will be published. If you think about those who are working on compilers and on different toolings, you understand why this matters so much. It further increases the needed predictability that developers working with compilers are widely represented among the committee members.
At the same time, people might feel that there are too many versions and it’s difficult to keep up to date. This criticism is valid on a certain level. Still, in comparison to Java or Python, it still gives plenty of leeways for us to keep ourselves up to date.
Conclusion
In this post, we discussed how the C++ programming language was born around 40 years ago. We saw how after the initial agility it lost a bit the momentum - at least in terms of evolution. C++ is a complex and widely used language and as such it’s governed by a multi-level organization. We saw how that organization is built-up and how the release pipeline is composed.
Since the release of C++11, the C++ Committee is committed to following a predictable schedule. There are new features and bug fixes released every three years. Thanks to those, C++ is evolving, it is now considered a modern programming language and it’s getting simpler to write correct code.
Connect deeper
If you liked this article, please
- hit on the like button,
- subscribe to my newsletter
- and let's connect on Twitter!
- if you're preparing for a C++ quant/trading interview, check out GetCracked